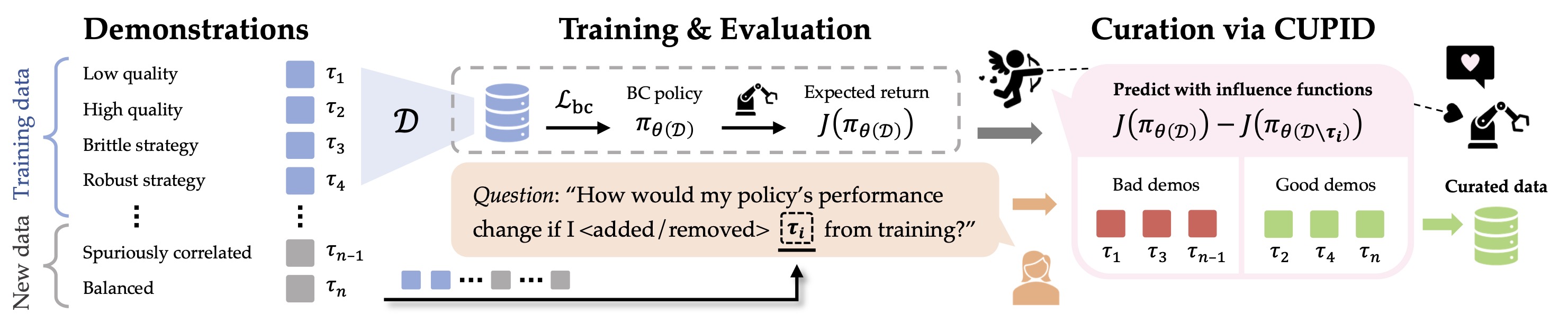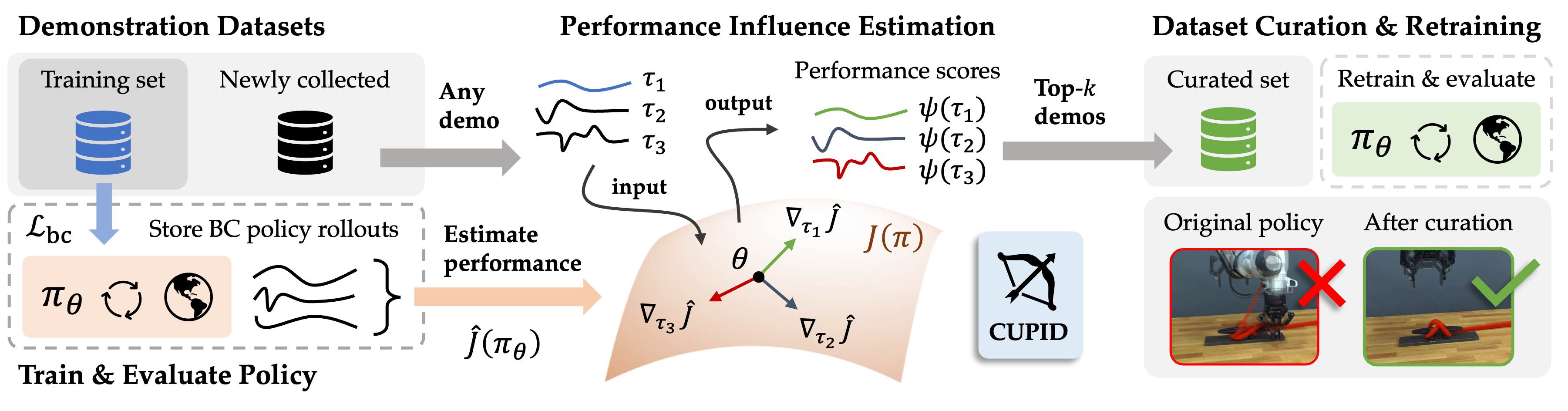
Improving Diffusion Policies by Debugging Training Data
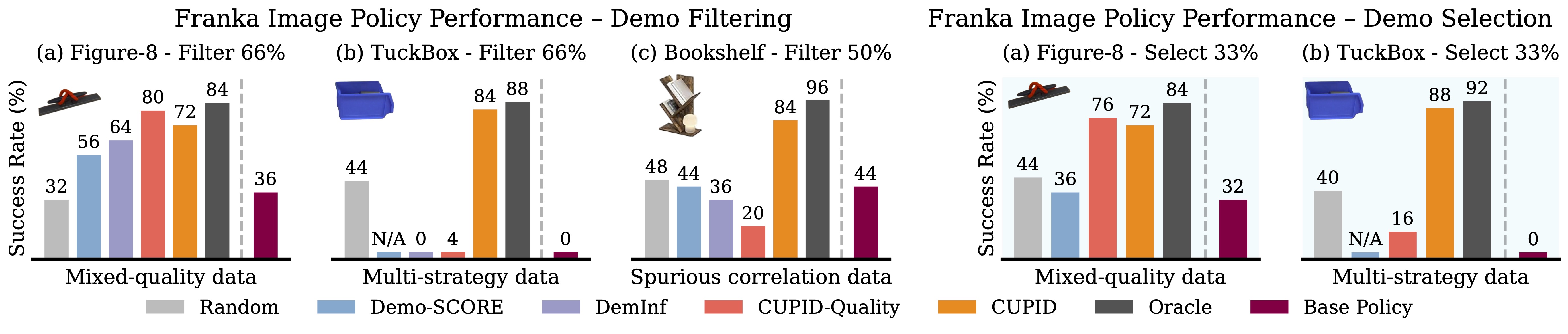

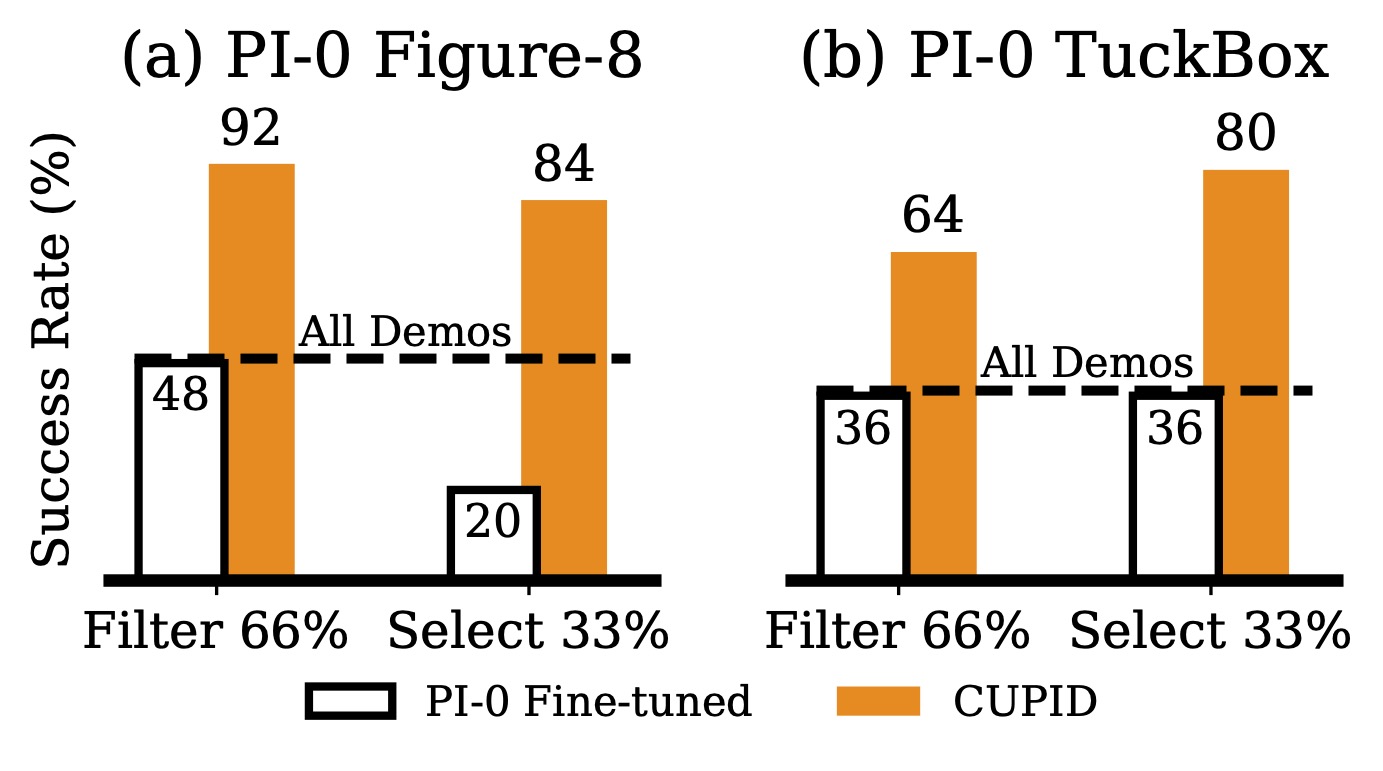
Franka real-world diffusion policy performance. CUPID, which curates demonstrations w.r.t. policy performance, improves success rates on mixed-quality datasets, identifies robust strategies, and disentangles spurious correlations that hinder performance. Although quality measures (e.g., DemInf, CUPID-Quality) help in mixed-quality settings (Figure-8), they degrade performance when higher-quality demonstrations induce brittle strategies at test time (TuckBox), or when quality is not the primary factor limiting policy success (Bookshelf). Overall, curating data based on performance (CUPID) maintains robustness across these settings. All data curation methods are limited to using 25 policy rollouts. Success rates are averaged over 25 rollouts.